

TikTokのバイトダンス、動画生成AI「MagicAnimate」を公開 簡単3ステップで写真を動画に

4人の女性が踊る動画がある。投稿されたショート動画だと思ったかもしれないが、そうではない。どれも本物の人間ではなく生成されたもの、それもたった1枚の写真(静止画像)から作られたものだ。

これはTikTok運営元のバイトダンス(字節跳動)とシンガポール国立大学による最新の研究成果、「MagicAnimate」と呼ばれる技術で作られたもので、1枚の静止画像と一連の動きの組み合わせから全く違和感のない動画を生成できる。MagicAnimateが公開されると、テック界に大きな衝撃が広がった。AI開発プラットフォーム「Hugging Face」のCTOまでが自身の画像を使って動画生成を体験している。

(https://twitter.com/julien_c/status/1731991225559920688)
「これでエクササイズしたことになるよね。今週はジムに行かずに済むよ」とユーモアたっぷりのコメントを添えた。
写真1枚でダンス動画を生成
開発チームはHuggingFaceに体験ページを設けている。操作はとても簡単で、まず人物の写真をアップロードし、次に生成したい動きのデモ動画をアップロードする。そしてパラメーターを調整して「Animate」ボタンをクリックする、という3ステップだけだ。
例えば下の画像は筆者の写真と、最近流行した「科目三」というダンスのショート動画で試してみたものだ。
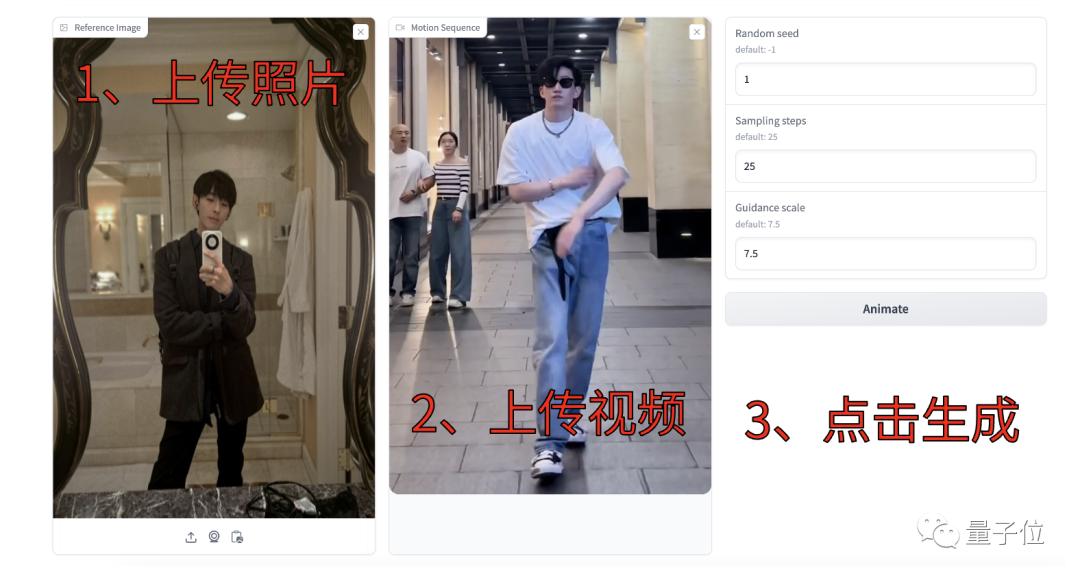
ショート動画プラットファーム・抖音(ID:QC0217)より
ページ下部のサンプルを利用することもできる。

ただMagicAnimateは現在人気がありすぎて、生成途中でフリーズしてしまうことがある。ソフトウエア開発プラットフォーム「GitHub」でも体験できるようになっており、興味がある人はそちらで試してもいい。
そのしくみは?
MagicAnimateは時間的一貫性を高め、参照画像のリアルさを維持し、アニメーションの忠実度を高めるために、拡散モデルを基礎とするフレームワークを採用した。

(論文:https://arxiv.org/abs/2311.16498)
開発チームはまず動画拡散モデル(Temporal Consistency Modeling)を開発して時間情報をエンコードした。拡散ネットワークに時間的特徴のモジュールを加えることで、時間情報をエンコードし、動画の各フレーム間の時間的一貫性を確保する。
次にフレーム間の外観一貫性を維持するために、新たに外観エンコーダ(Appearance Encorder)を導入して参照画像を細部まで保つようにした。OpenAIが開発した事前学習画像分類モデル「CLIP」のエンコード方法とは異なり、視覚的特徴を抽出して動画をガイドする。こうすることで身体や背景、衣服などの情報をより正確に保持することができる。
開発チームはこの2つの新技術をベースに、簡単な映像融合技術も使って長い動画のトランジションをなめらかにした。時間と外観の一貫性に関する実験の結果、MagicAnimateはこれまでの方法に比べはるかに優れていることが分かった。特に難易度が高いTikTokのダンスのデータセットでは、既存の最高レベルの方式に比べてMagicAnimateの動画の忠実度が38%あまり上回っている。
このようなサービスは最近とても人気がある。MagicAnimateが公開される少し前には、アリババグループ傘下の研究機関も同じように静止画像1枚と動きから動画を生成する「Animate Anyone」を発表している。

作者:量子位(WeChat公式ID:QbitAI)、金磊
(翻訳・36Kr Japan編集部)

関連記事




関連キーワード
日本企業のDXを促進するプラットフォーム「CONNECTO」
無料コンテンツ公開中







AIドラマ、中国文化の海外進出を後押しXxjjpbJ000023_20260323_CBPFN0A001207.png)
