原文はこちら
セミナー情報や最新業界レポートを無料でお届け
メールマガジンに登録
中国IT大手アリババグループのクラウド事業「アリババクラウド(阿里雲)」は12月1日、大規模言語モデル(LLM)「通義千問(Tongyi Qianwen)」をバージョン2.1にアップデートし、同時に「Qwen-72B」「Qwen-1.8B」「Qwen-Audio」という新たなモデル3つを発表した。
中でも注目の的となったQwen-72Bは、720億のパラメーターを持ち、3兆トークンもの高品質データでトレーニングを施してある。アリババクラウドによると、Qwen-72Bは主要な10のベンチマークテストで、オープンソースLLMとしては最高スコアを叩きだし、一部の指標ではクローズドソースのGPT-3.5やGPT-4を上回った。
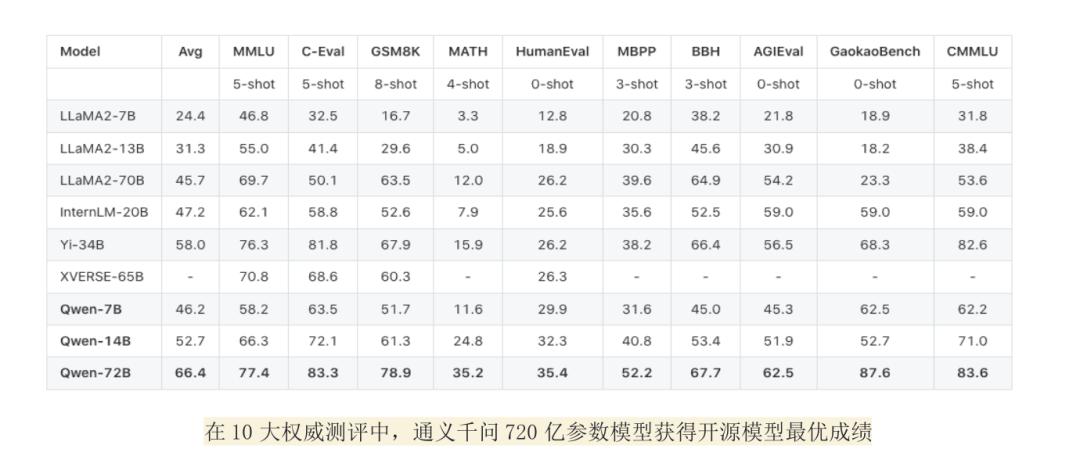
英語のタスクでは、マルチタスク言語理解を評価するベンチマークMMLUで、オープンソースLLMのうち最高スコアを獲得した。中国語のタスクでは、C-EvalやCMMLU、GaokaoBenchなどの中国語性能を測るベンチマークでGPT-4を上回るスコアを出した。
さらに、数学的推論ベンチマークのGSM8KとMATHを使った性能評価では、他のオープンソースLLMを大きくリードしたほか、コード生成を評価するベンチマークHumanEvalやMBPPでも優れた性能を見せた。
現在のLLM開発は、クローズドソースとオープンソースの2種類に分かれている。ChatGPTで一躍有名になった米OpenAIはクローズドソース路線、一方のオープンソースで代表的なのは米Metaの「Llama」だ。Metaは今年7月「Llama2」を公開し、パラメーター数が70億、130億、700億の3モデルを用意した。
今回Qwen-72Bが公開されたことで、中国市場にはLlama2をベンチマークとする高性能のオープンソースLLMがまた1つ加わった。現在アリババが公開しているLLM通義千問シリーズは、パラメーター数18億、70億、140億、720億など全てのモデルがオープンソース化されている。
異なるパラメーターサイズのモデルをそろえることで、活用シーンをさらに広げることができる。720億パラメーターを誇るQwen-72Bは、中・大規模企業が商用アプリケーションを開発する際に利用したり、大学や研究機関がAIを研究に活用したりする場面など、複雑な演算を必要とする作業に役立てることができる。実際、華東理工大学の研究室「X-D Lab」は、通義千問をベースにメンタルヘルス向け「MindChat(漫談)」、ヘルスケア向け「Sunsimiao(孫思邈)」、教育・受験向け「GrandChat(錦鯉)」などの対話型AIを開発した。これまでに20万人以上が利用し、X-D Labが提供した回答サービスは100万回を超えるという。
加えて、アリババクラウドはパラメーターサイズの小さいQwen-1.8Bも公開した。2000トークンのテキストを推論するのに必要なGPUメモリはわずか3ギガと、スマートフォンやパソコンといった消費者向けデバイスのスペックでも利用できる。
パラメーターサイズの巨大なLLMは高い演算能力を必要とするため、クラウド上でしか運用できない。LLMをもっと多くのデバイスで使えるようにするため、このところLLM開発企業やスマホ・パソコンメーカーはより軽量のLLMを模索している。Qwen-1.8Bはスマホやパソコンなどのデバイスを使ってオフラインで実行でき、テキストや画像などの軽いタスクなら十分に対応できるという。
さらにマルチモーダル分野の模索として、音声入力に対応した「Qwen-Audio」も公開された。人の声や自然音、動物の鳴き声、音楽などあらゆる種類の音声を感知し、理解できるというものだ。ユーザーが入力した音声を理解して、それを基に推論したり、ストーリーの続きを作成したりできる。
今や通義千問は「見る」だけでなく「聞く」ことも可能になり、いっそう賢くなった。今年8月公開の画像理解能力を持つ「Qwen-VL」も、多くの面で機能の向上が見られた。汎用OCR(光学文字認識)や視覚推理、中国語テキストの理解能力が向上したほか、さまざまな解像度やフォーマットの画像を処理できるようになり、画像を見て問題を解くことも可能になった。
(翻訳・畠中裕子)
原文はこちら
セミナー情報や最新業界レポートを無料でお届け
メールマガジンに登録