



Related tags :
セミナー情報や最新業界レポートを無料でお届け
メールマガジンに登録
続きを読む
中国ネット大手の百度(バイドゥ)がこのほど公開したオープンソースのマルチモーダルドキュメント解析モデル「PaddleOCR-VL」が、ドキュメント解析ランキング「OmniBenchDoc V1.5」で92.6点を獲得し、総合性能で世界1位となった。
テキスト、表、式、読み順の4つの主要性能のいずれもが、GPT-4oやGemini-2.5 Pro、Qwen2.5-VL-72Bなど現在主流のマルチモーダルモデルを上回ったほか、ドキュメント解析モデルのMonkeyOCR-Pro-3BやMinerU2.5、dots.ocrを超え、世界記録を塗り替えた。
PaddleOCR-VLは、バイドゥ独自の大規模言語モデル(LLM)「文心(ERNIE)4.5」の派生モデルで、コアモデルはわずか9億パラメータ(0.9B)と軽量かつ高効率。テキストや手書きの漢字、表、公式、グラフなど複雑な要素を、極めて低い計算コストで正確に識別できる。中国語や英語、フランス語、日本語、ロシア語、アラビア語、スペイン語など109種類の言語に対応し、政府や企業のドキュメント管理や知識検索、文書のデジタル化、研究情報の抽出などに幅広く活用できる。
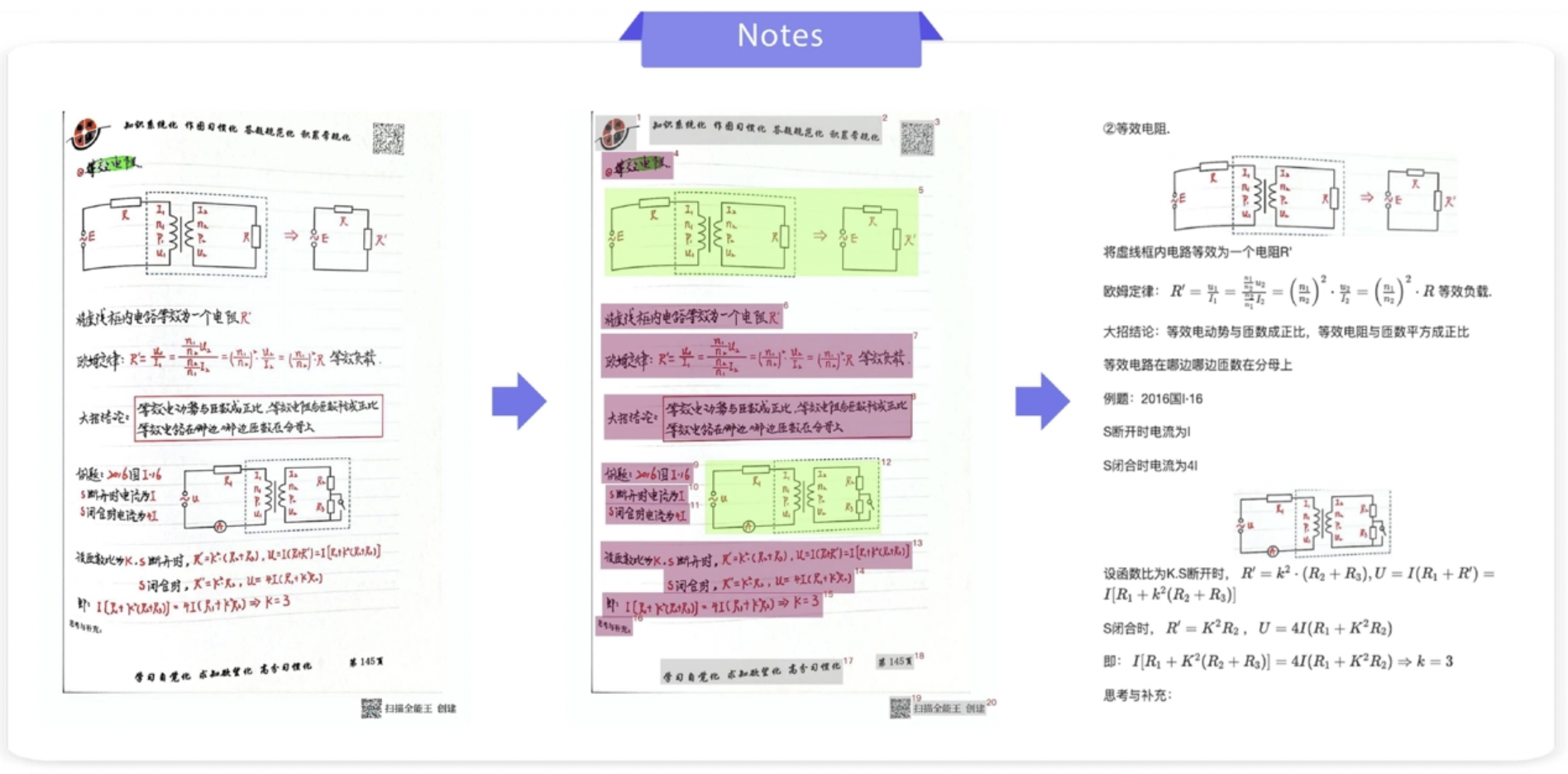
従来のドキュメント解析モデルが文字を識別するだけだったのに対し、PaddleOCR-VLは文書の複雑な構成を理解することが可能。決算報告書の表、数学の公式、手書きの授業ノートなどの内容を正確に読み取り、ロジックを混乱させることなくタイトルや本文、図版、注釈などを完全に再現できる。
(36Kr Japan編集部・茶谷弥生)
セミナー情報や最新業界レポートを無料でお届け
メールマガジンに登録



















中国ティードリンク「喜茶」、カナダ初のコンセプト店オープンXxjjpbJ000094_20260225_CBPFN0A001347-510x369.jpg "中国ティードリンク「喜茶」、カナダにコンセプト店「Lab」開設 北米展開を加速")
、4年連続で黒字達成 AIGCでコンテンツ強化へ")
