

アリババクラウド、音声認識モデル「Qwen3-ASR-Flash」公開 精度でGoogleやOpenAIを凌駕
公開日:
中国アリババグループ傘下のアリババクラウドは9月8日、最新の音声認識モデル「Qwen3-ASR-Flash」を発表した。同モデルは、中国語や英語、フランス語、日本語など11言語と多様なイントネーションに対応する。アリババクラウドの「ModelScope」のほか、「HuggingFace」などのオープンソースプラットフォームを通じて無料で利用できる。
Qwen3-ASR-Flashは大量のマルチモーダルデータと数千万時間分の自動音声認識(ASR)データに基づいて構築されており、言語を自動識別し、無音の部分や背景ノイズの部分などを自動的にフィルタリングする。
ASRモデルのベンチマークテストの結果、Qwen3-ASR-Flashは方言や多言語、重要情報、歌詞などの音声認識のエラー率が、グーグルの「Gemini-2.5-Pro」やOpenAIの「GPT-4o-Transcribe」、バイトダンスの「豆包(Doubao)ASR」などを大幅に下回った。
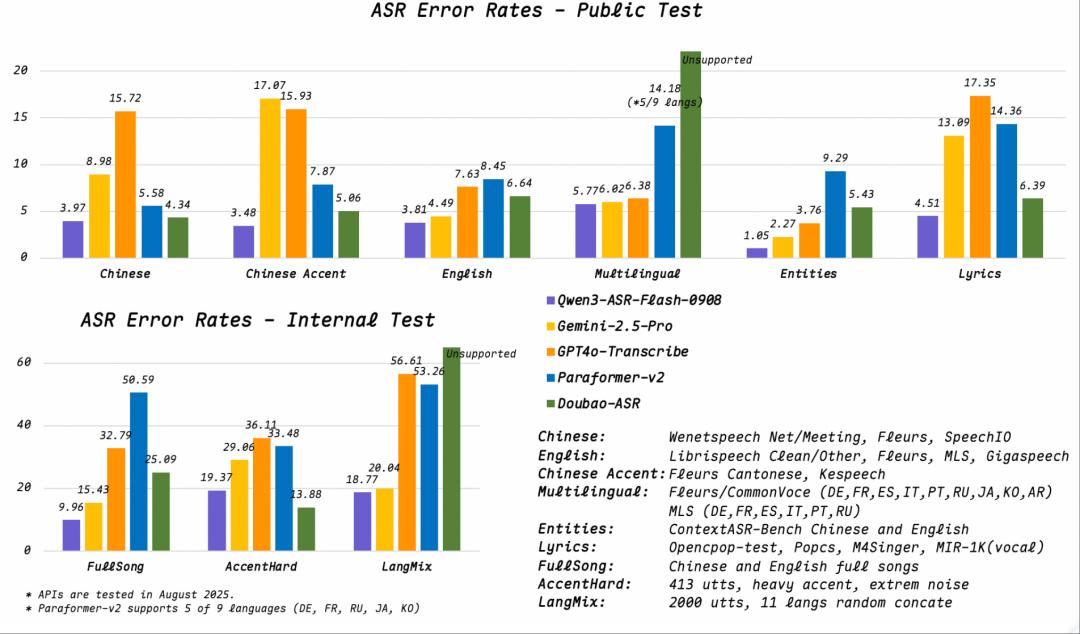
Qwen3-ASR-Flashについては、多様なノイズ、多言語、方言、専門用語の認識など、さまざまなデモ例が公開されている。たとえば、英語や日本語など5つの言語を含む音声を正確に文字起こしできるほか、アカペラと伴奏付きの楽曲の歌詞の書き起こしにも対応しており、研究者の実測によるエラー率は8%を下回った。

(36Kr Japan編集部)

関連記事




関連キーワード
日本企業のDXを促進するプラットフォーム「CONNECTO」
無料コンテンツ公開中








メークブラシ産業の発展推進、世界で大きなシェア-河南省鹿邑県XxjjpbJ000039_20260611_CBPFN0A001198-scaled.jpg)

