

米最新のLLM評価基準、アリババの「Qwen2-72B」がトップ10入り 中国企業で唯一
公開日:

米国の人工知能(AI)企業「Abacus.ai」、ニューヨーク大学、エヌビディア、メリーランド大学、南カリフォルニア大学のチームがこのほど、大規模言語モデル(LLM)の性能を評価する新たなベンチマーク「LiveBench」を発表した。開発には、ニューヨーク大学教授で米メタのチーフAIサイエンティストを務めるヤン・ルカン氏も参画した。同氏はコンピューター科学のノーベル賞とされる「チューリング賞」の受賞者としても知られている。
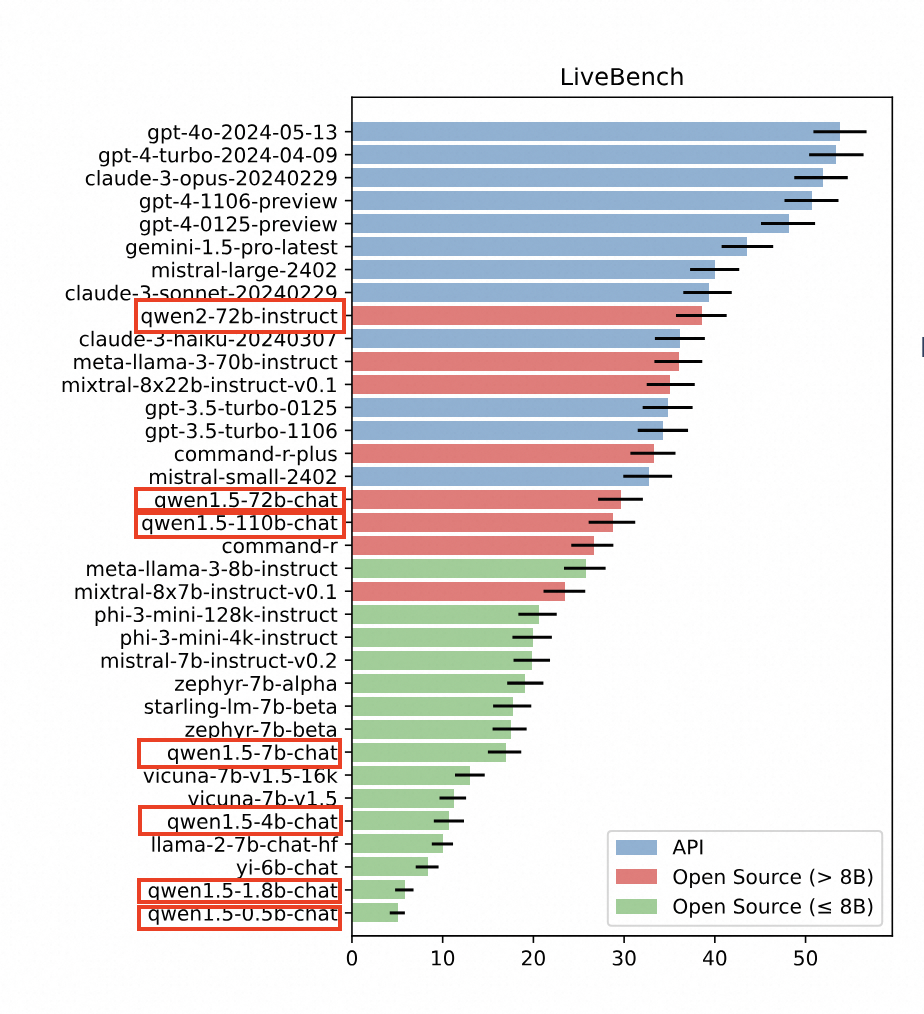
LiveBenchの最初の評価は、世界をリードする34のオープンソースおよびクローズドソースのLLMを対象に実施された。1位は米OpenAIの「GPT-4o」だった。2位以下は、米アンソロピックの「Claude 3」、米グーグルの「Gemini-1.5」、中国アリババグループの「Qwen2-72B」と続いた。Qwen2-72Bは、オープンソースモデルでは最上位となり、中国のLLMで唯一トップ10に入った。
Qwenシリーズからは計7つのモデルがランクイン、OpenAIのGPTシリーズに次ぐ多さだった。Qwenシリーズのオープンソースモデルは、これまでに1600万回以上ダウンロードされている。
(36Kr Japan編集部)

関連記事




関連キーワード
日本企業のDXを促進するプラットフォーム「CONNECTO」
無料コンテンツ公開中





中国で水素車普及進む-東風汽車、累計9200台超投入XxjjpbJ000076_20260605_CBPFN0A001718-scaled.jpg)





